
Unity&Pythonで機械学習の準備は整っただろうか?まだの人は以下のリンクから環境を整えてもらいたい
○Windows編
○Mac編
サンプルシーンを使って学習させてみる
ではさっそく機会学習をさせてみよう。いきなりすべてを行うのは大変なのでまずはサンプルシーンを使って機械学習の流れを学習する。
確認
まずは3DBallのシーンを再生してみよう。

ボールを落とさないようにうまくバランスを取っている。これは学習済みのデータがセットされているからだ。
学習データを外す
学習データを外してみよう。prefabsフォルダの3DBallをダブルクリックしてプレファブ編集モードに入る
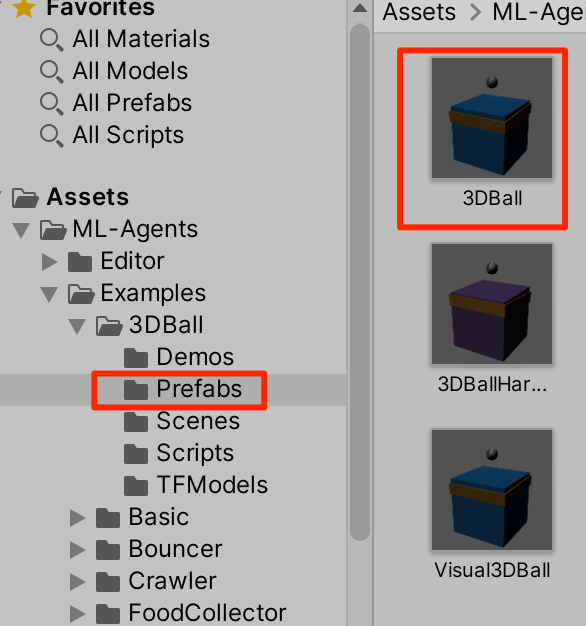
AgentをクリックしてみるとBehaviorParametersというコンポーネントがあって、そこのModelに3DBall(NNModel)というのが付与されている。これが学習済みデータだ。
マルぽちを押してNoneを選択する。
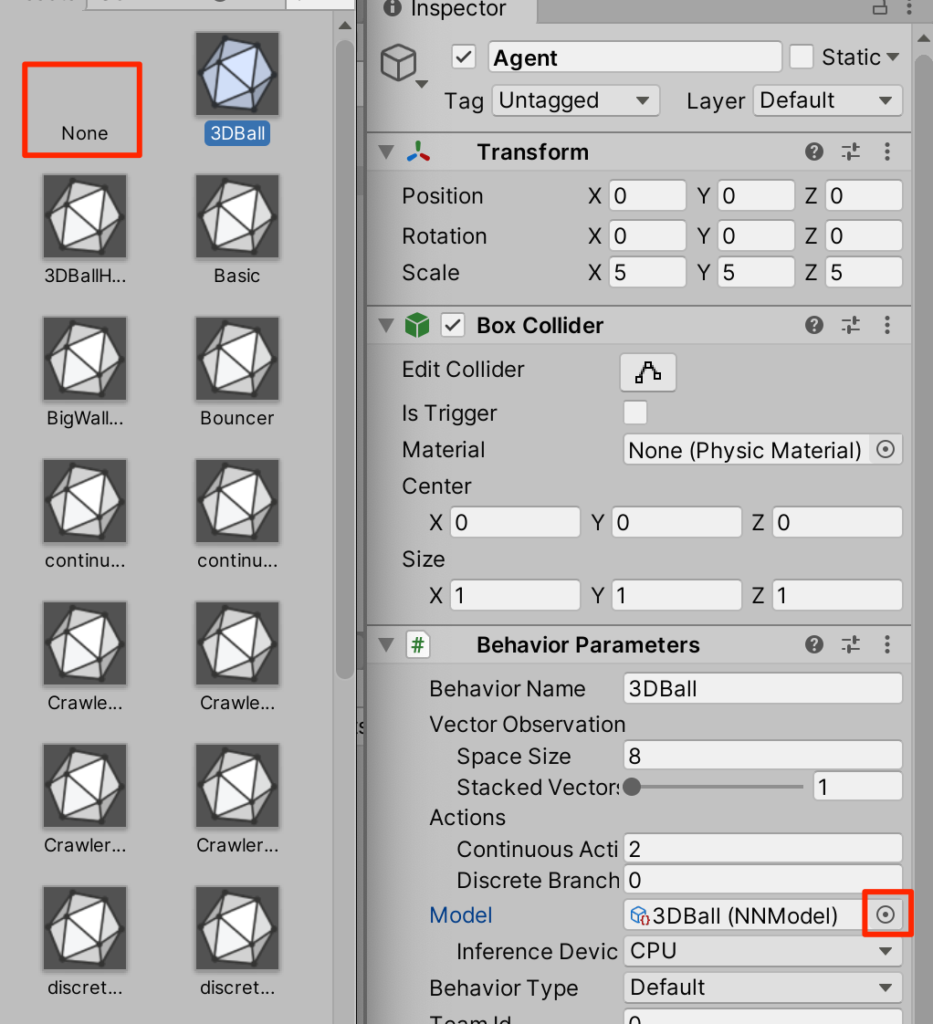
自分でやってみる。。。
これで学習データが取り外された。実行してみよう、矢印キーで操作できるのでボールを落とさないように操作してみよう!12個全てが同期して動いてしまうのでどれか一つに注目して操作するのがポイントだ。

難しい・・・
機械学習させる
仮想環境に入って。GitHubからクローンしたフォルダに移動し、以下のコマンドを打つ
(ballTest1というのは任意のID)
$ mlagents-learn config/ppo/3DBall.yaml --run-id=ballTest1

○ML-Agentが立ち上がるのでUnityを実行する。
○最初はポロポロ落としていたが、次第に上達していっているのがわかる(Mean Rewardは平均報酬)
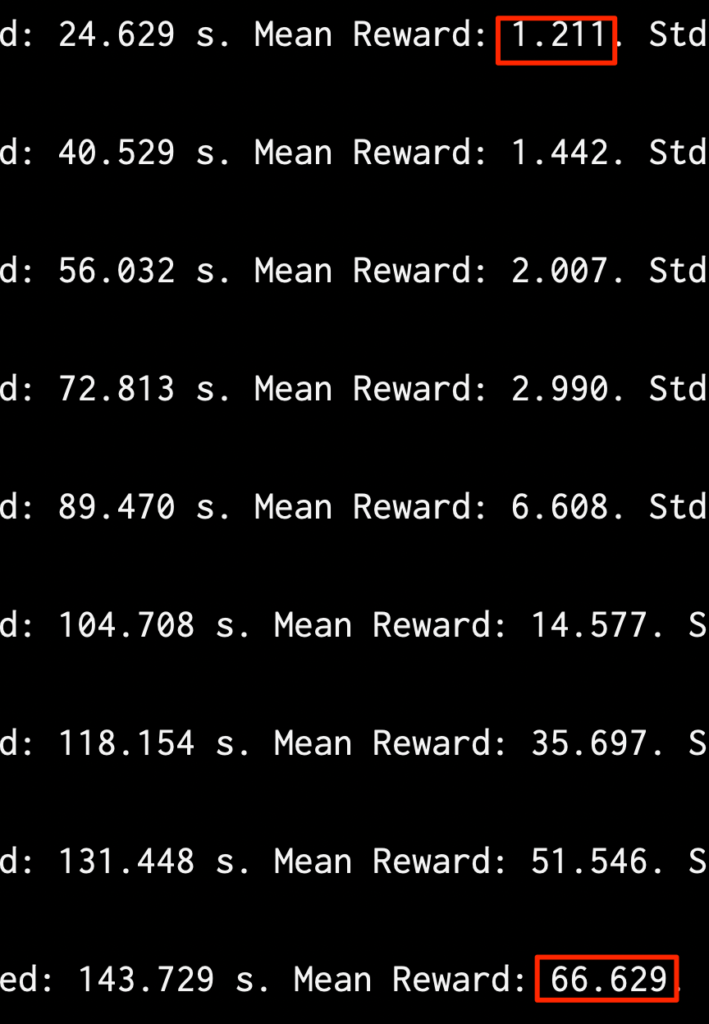
学習終了
約12分かけて50万ステップの学習が終了しました。(時間はマシンスペックに依存)
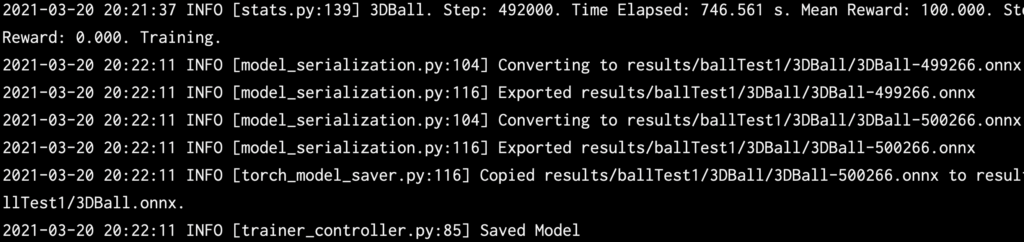
作成されたデータ場所
作成された学習データは
ml-agents->results->ballTest1
の中にある。
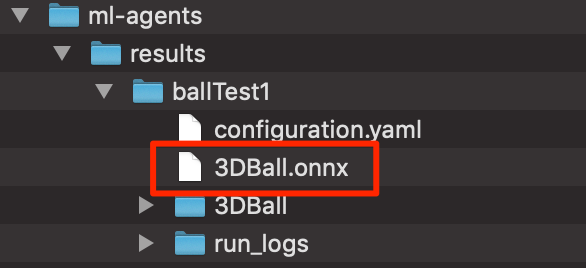
配置
このonnxファイルを
3DBall->TFModesフォルダの中にドラッグ&ドロップで配置する
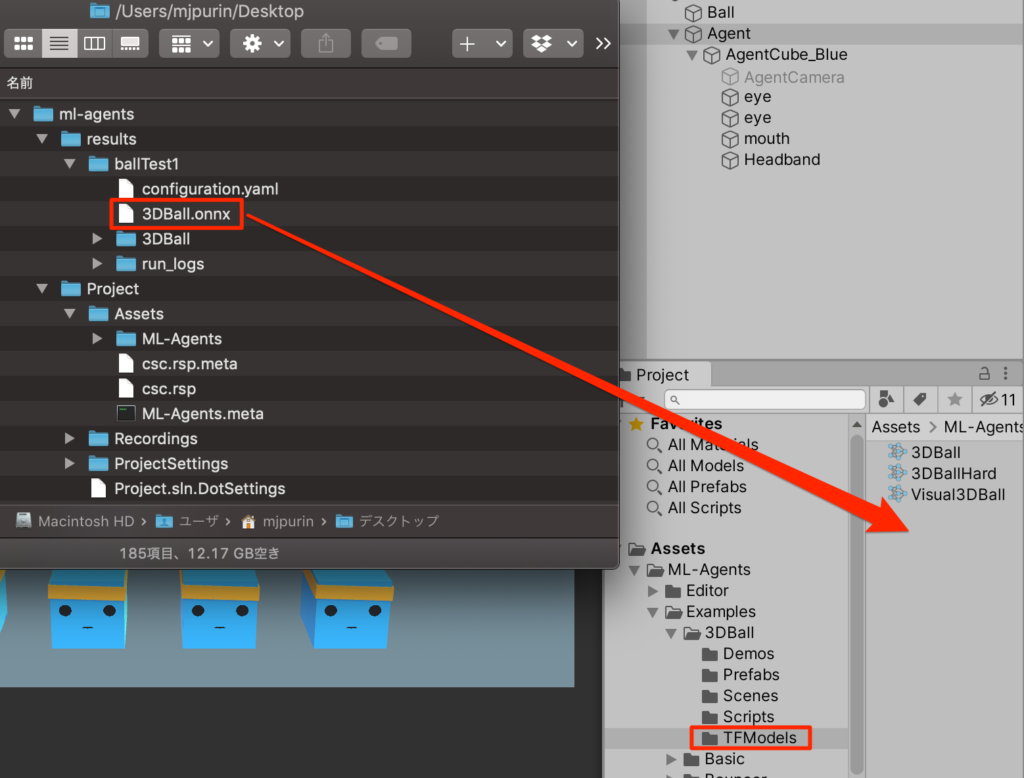
プレファブにアタッチ
3DBallプレファブをプレファブ編集モードで開いて、AgentsのBehaviorParametersにあるModelに今作成したデータをアタッチする。
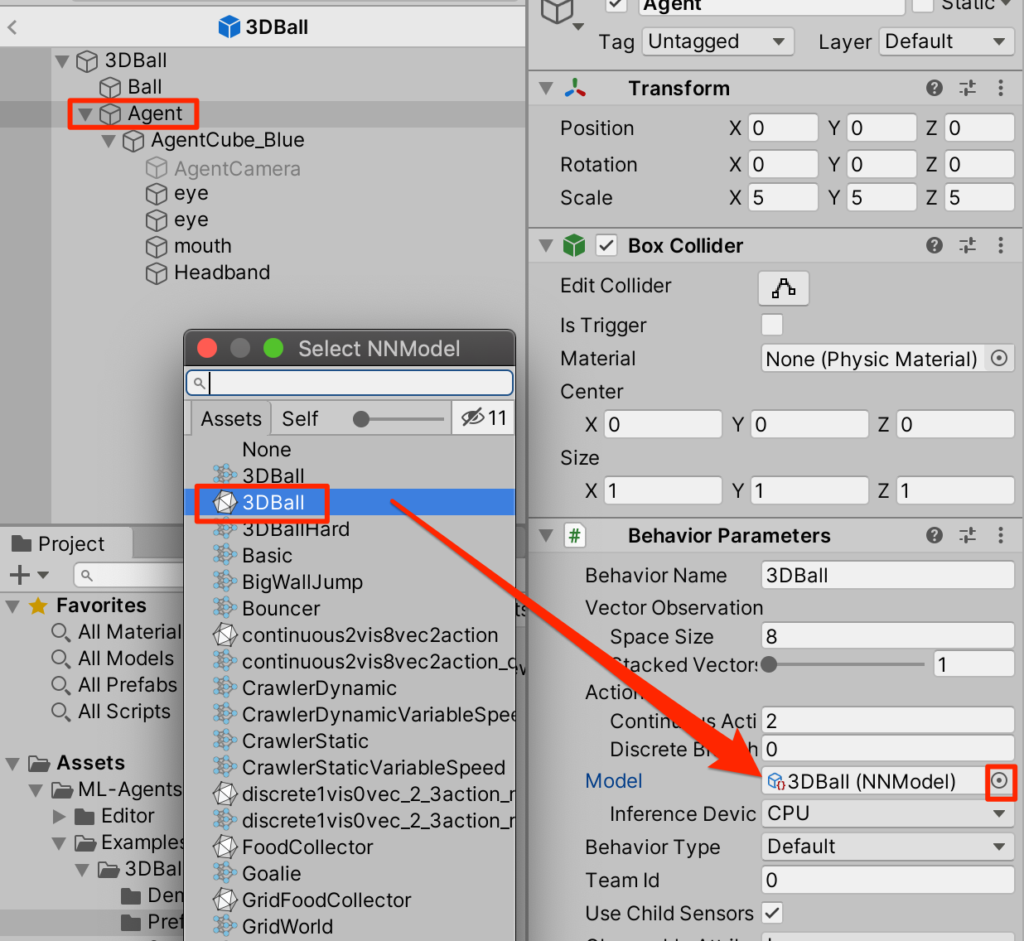
いざ実行!
50万ステップの学習によって、ボールを全く落とさなくなった!
ウルトラスムーズ!
トレーニングの進捗状況の観察
ml-agentsフォルダにresultsフォルダが作成されているのでまずはml-agentsフォルダに移動する。
$ cd ~/desktop/ml-agents
トレーニングプロセスをより詳細に観察するために、TensorBoardを使用できる。コマンドは以下
$ tensorboard --logdir results
ブラウザで確認してみよう。アドレスは以下
localhost:6006
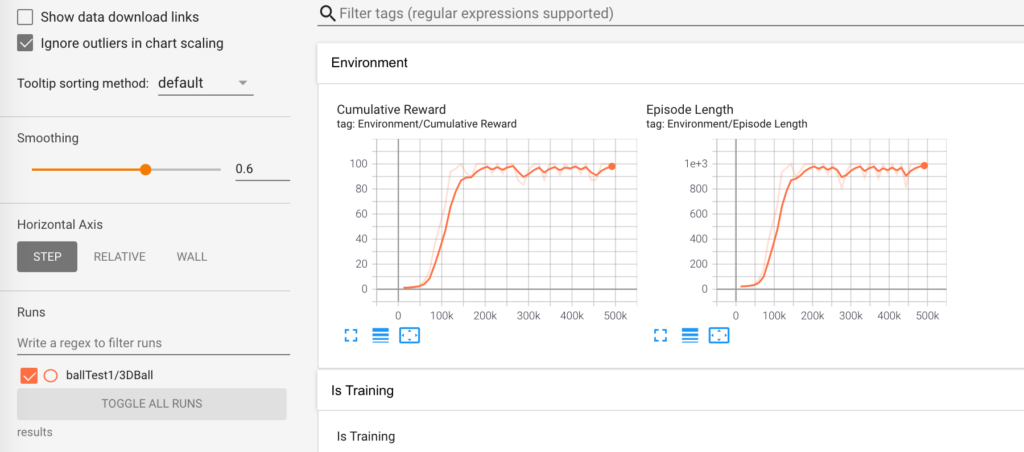
注目すべきはCumulative Reward(累計報酬)
エージェントが獲得できる最大報酬に収束していく。このグラフを見ると20万ステップほどでほぼ学習ができていることがわかる。
終わりに
今回はサンプルデータを用いて学習ファイルの作成方法とアタッチの仕方を学んだ。
次回はいよいよ1から作成していく。お楽しみに!


コメント