
エクリプス動的WebプロジェクトにおいてDBに接続する流れを理解しよう。
今回はWebアプリにおけるDBのアクセスを効率的に処理できるコネクションプールを利用していく。
データベースのコネクションプールとは、データベースとの接続を効率的に管理する仕組みです。具体的には、アプリケーションがデータベースに接続するための「接続」のリソースを事前に一定数作成しておき、その接続を再利用することでパフォーマンスを向上させるものです。
コネクションプールの仕組み
- 接続のプール: アプリケーションが起動する際、データベースとの接続があらかじめ一定数作成され、プール(プールというのは、いわば「たまり場」のようなもの)に保持されます。
- 接続の再利用: アプリケーションがデータベースにアクセスしたい場合、新たに接続を作成するのではなく、プールにある接続を借りて使用します。使用後は接続をプールに戻します。
- 効率の向上: 新しい接続を作成するコスト(時間やリソース)が削減されるため、データベースへのアクセスが迅速になります。また、コネクションの数を制限することで、データベースの負荷も管理しやすくなります。
メリット
- パフォーマンスの向上: 接続の再利用により、接続の確立にかかる時間やリソースが節約できます。
- リソースの節約: 同時にデータベースへの接続数を制限することで、サーバーのリソースを適切に管理できます。
- 簡単な管理: コネクションプールは通常、自動で管理されるため、開発者が一つ一つの接続を手動で扱う必要がありません。
簡単に言うと、コネクションプールは「接続の予約席」を用意して、効率的に接続を管理するための仕組みです。
前提条件
Eclipse2023(Java21 + Tomcat10) * バグフィックス済み
XAMPPv3.3.0(Apache/2.4.58 + PHP/8.2.12 + MariaDB10.4.32)
MariaDB用 jdbcダウンロード済
接続チェック用DB(lunchapp)作成済
DB起動済
動的Webプロジェクト作成
エクリプスにて新規動的Webプロジェクトから[lunchapp]を作成する。
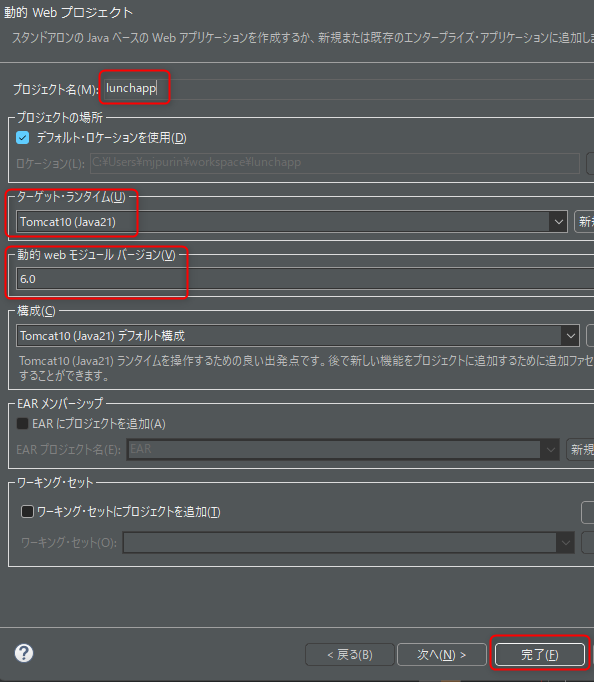
jdbcドライバの配置
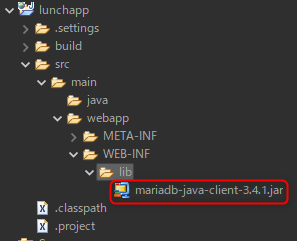
src -> main -> webapp -> WEB-INF -> lib にダウンロード済みのjdbcドライバを配置する。(*配置する場所を間違えないこと)
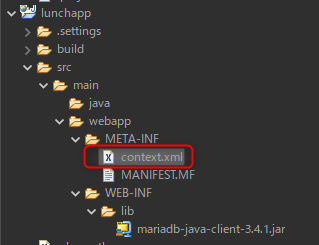
context.xmlの作成
META-INFを右クリックして、新規ファイルより[context.xml]を作成する。(*場所、ファイル名を間違わないこと)
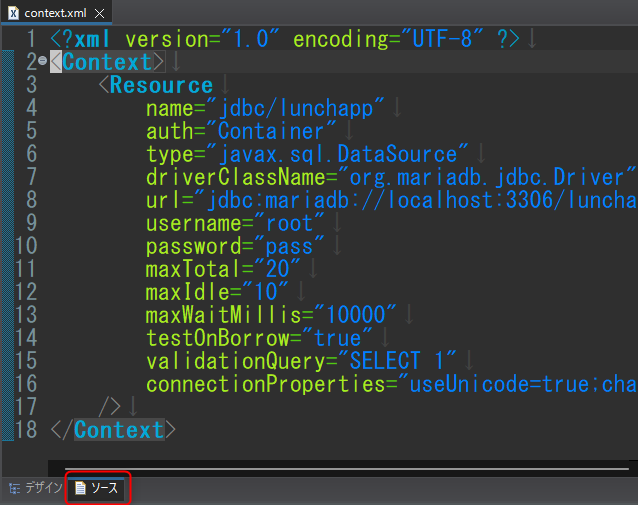
context.xmlの内容は以下。(*コピペ推奨)
<?xml version="1.0" encoding="UTF-8" ?>
<Context>
<Resource
name="jdbc/lunchapp"
auth="Container"
type="javax.sql.DataSource"
driverClassName="org.mariadb.jdbc.Driver"
url="jdbc:mariadb://localhost:3306/lunchapp"
username="root"
password="pass"
maxTotal="20"
maxIdle="10"
maxWaitMillis="10000"
testOnBorrow="true"
validationQuery="SELECT 1"
connectionProperties="useUnicode=true;characterEncoding=UTF-8;"
/>
</Context>name:
データソースの JNDI 名前で、アプリケーションからリソースを参照するために使用されます。
例) jdbc/lunchapp
auth:
認証の種類を定義します。通常は "Container" に設定され、コンテナが認証を処理します。
例) Container
type:
リソースのクラス名を指定します。データソースの場合は通常、javax.sql.DataSource です。
例) javax.sql.DataSource
driverClassName:
データベースに接続するための JDBC ドライバのクラス名を指定します。
例) org.mariadb.jdbc.Driver
url:
データベースに接続するための JDBC URL です。データベースの場所や名前を含みます。
例) jdbc:mariadb://localhost:3306/lunchapp
username:
データベースに接続するためのユーザー名を指定します。
例) root
password:
データベースに接続するためのパスワードを指定します。
例) pass
maxTotal:
プール内で許可される最大アクティブ接続数を指定します。
例) 20
maxIdle:
プール内で保持する最大アイドル接続数を指定します。
例) 10
maxWaitMillis:
接続プールが接続を取得するまでの最大待機時間(ミリ秒)を指定します。
例) 10000 (10秒)
testOnBorrow:
接続をプールから取得する際に、その接続が有効かどうかをチェックするかどうかを指定します。true に設定すると、接続が使用される前に検証されます。
例) true
validationQuery:
接続の有効性を確認するための SQL クエリを指定します。通常、簡単で迅速に実行できるクエリが使われます。
例) SELECT 1
connectionProperties:
接続に関する追加のプロパティを指定します。これらは JDBC ドライバやデータベースに特有の設定です。
例) useUnicode=true;characterEncoding=UTF-8;注意)context.xmlに入力する際、テキストが打ち込めないときは下部にあるタブからソースを選択する
なお、usernameとpasswordのところはDBに接続できるユーザーとパスワードを設定すること(DBへのユーザー設定はこちら)
DAOの作成
準備が整ったのでJavaファイルを作成していく。
dao.LunchAppDataSource.java
新規クラスからdao.LunchAppDataSource.javaを以下のように作成する。
package dao;
import java.sql.Connection;
import java.sql.SQLException;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.sql.DataSource;
public class LunchAppDataSource {
public Connection getConnection() throws NamingException, SQLException {
InitialContext ctx = new InitialContext();
DataSource ds = (DataSource)ctx.lookup("java:comp/env/jdbc/lunchapp");
return ds.getConnection();
}
}ポイント
先ほど作成context.xmlの情報をもとにDBと接続するクラス。
ctx.lookupの引数の文字列”java:comp/env/jdbc/lunchapp“とあるが下線部がcontext.xmlのname属性 [jdbc/lunchapp]と一対一で対応している。それ以外のjava:comp/env/は毎回共通だ。
util.ConnectCheck.java
新規サーブレットからutilパッケージ内にConnectCheck.javaを以下のように作成する。(*コピペ推奨)
package util;
import java.io.IOException;
import java.io.PrintWriter;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import javax.naming.NamingException;
import dao.LunchAppDataSource;
import jakarta.servlet.ServletException;
import jakarta.servlet.annotation.WebServlet;
import jakarta.servlet.http.HttpServlet;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
@WebServlet("/ConnectCheck")
public class ConnectCheck extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/plain");
PrintWriter out = response.getWriter();
String sql = """
SELECT *
FROM lunches
""";
try(Connection db = new LunchAppDataSource().getConnection();
PreparedStatement ps = db.prepareStatement(sql);
ResultSet rs = ps.executeQuery()){
while(rs.next()) {
out.println(rs.getString("shop")+":"+rs.getString("menu"));
}
} catch (SQLException | NamingException e) {
//エラーメッセージを出力
out.println("error: " + e.getMessage());
//スタックトレースをブラウザに出力
e.printStackTrace(out);
}
}
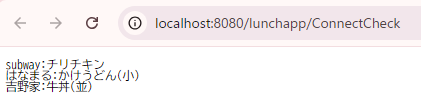
}サーブレットを実行してみよう。すべてに問題がなければ以下のようにブラウザに3件のデータが表示されるはずだ。
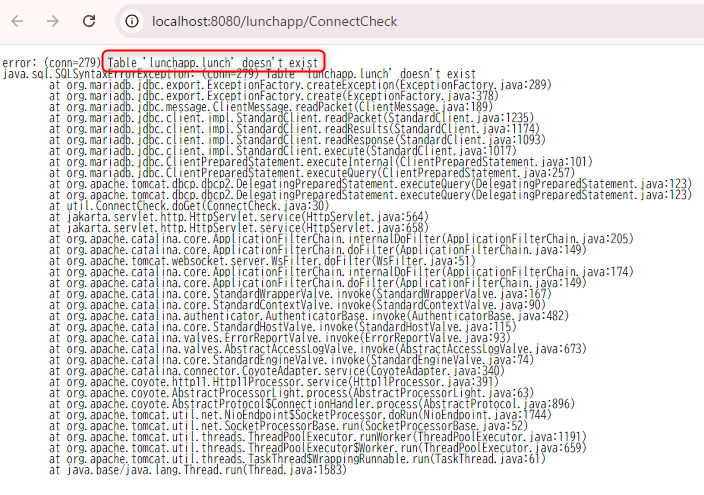
もしエラーが出た場合はメッセージとスタックトレースが表示されるのでエラーを修正しよう。ここではlunchapp.lunchというテーブルは存在しないというエラーが出ている。SQL文においてテーブル名をlunchesとしなければならないところlunchとしてしまった場合こうなる。
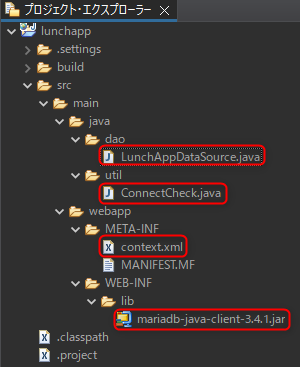
エラーが出た際にはファイルの配置場所が間違えていないかよく確認してもらいたい。
ポイント
ここはあくまで接続チェックを行っているだけなので詳細は気にすることはない。接続ができればオールOKだ。詳細に関しては次回以降作成していく。
最難関クリア
無事に表示されれば、Java + SQL の最難関をクリアしたと言って良い。
初学者においてこの環境を設定しく作業はとても難しい。
次回以降は実際にブラウザ上からDBにデータ登録、一覧、更新、削除(いわゆるCRUD)ができるようにしていく。
コメント